
作者:郭耀龙,新炬网络高级技术专家。
传统关系型数据库由于缺乏扩展性,在面对大数据时存在巨大的缺陷,但是关系模型、事务机制对于大部分系统又不必不可少,目前业界主流的做法就是将传统数据库进行切分(包括垂直切分、水平切分等),提高数据库的可扩展性。但是切分之后又带来了新的问题,比如多数据源管理问题、跨节点join问题、分布式事务问题等。下面探讨Mycat如何解决这些问题。
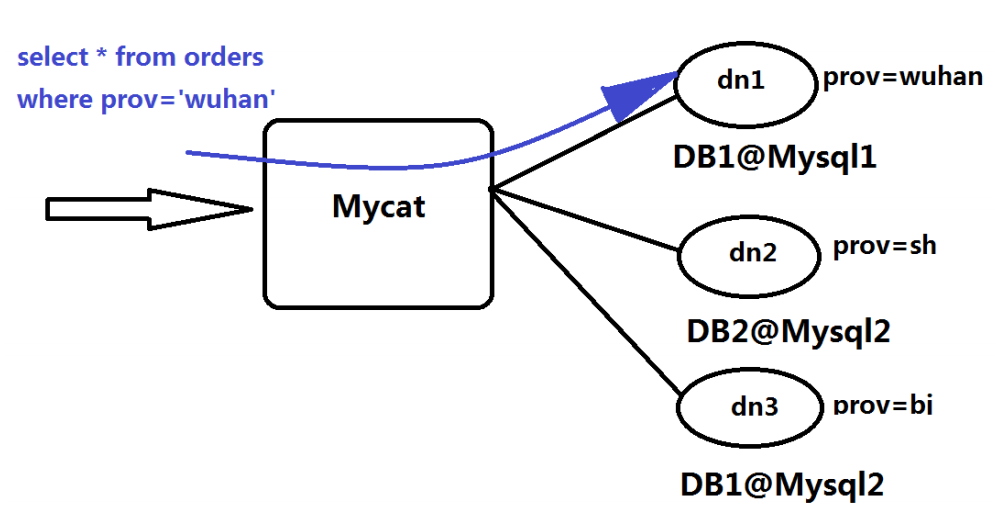
针对多数据源管理问题,主要有两种解决思路,第一:客户端模式,在每个应用程序模块中配置管理自己需要的一个(或者多个)数据源,直接访问各个数据库,在模块内完成数据的整合。第二:通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明。第一种方式不具备通用性,每个应用程序都需要自行开发数据整合功能,且对于已经建设完成的系统需要进行代码重构,不适宜推广。目前主要使用的是第二种方式,Mycat的原理如下:Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
Mycat的原理与其他分布式数据库中间件很类似,但是在架构上还是有区别,Mycat来源于Cobar,但在其基础上进行了很大改进,Mycat的架构如下:
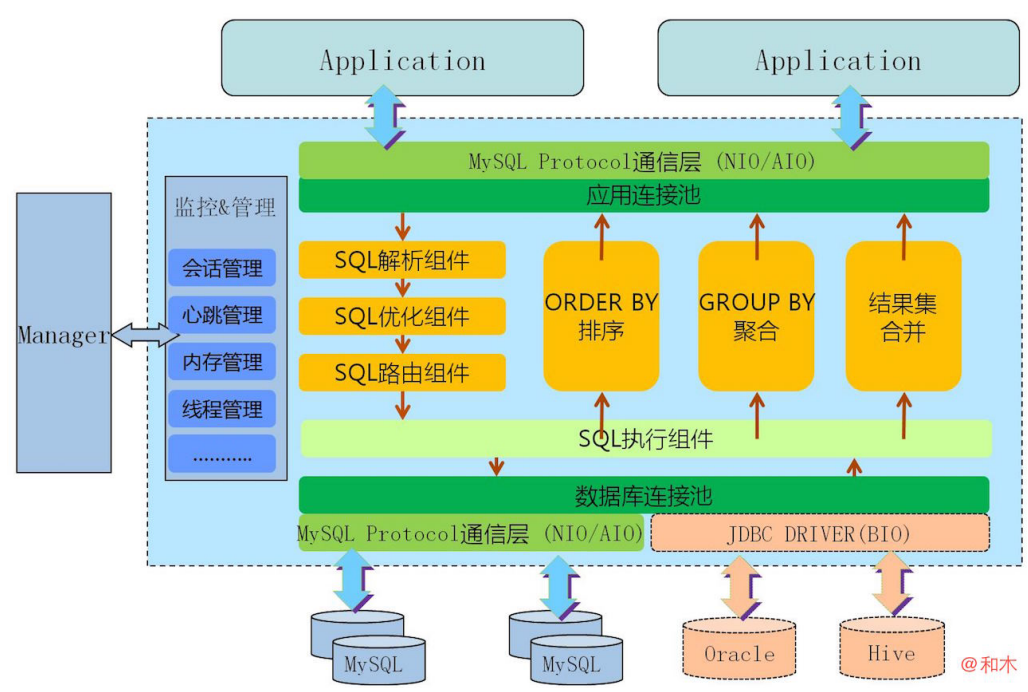
目前主流的分布式数据库中间件还有TDDL、Amoeba、Coba等,TDDL不同于其它几款产品,并非独立的中间件,只能算作中间层,是以Jar包方式提供给应用调用。属于JDBC Shard的思想,网上也有很多其它类似产品。Amoeba是作为一个真正的独立中间件提供服务,即应用去连接Amoeba操作MySQL集群,就像操作单MySQL一样,从架构中可以看来,Amoeba算中间件中的早期产品,后端还在使用JDBC Driver。Cobar是Amoeba基础上进化的版本,一个显著变化是把后端JDBC Driver改为原生的MySQL通信协议层,这就意味着不能支持Oracle、ProstgreSQL等主流数据库。MyCat又是在Cobar基础上发展的版本,后端由BIO改为NIO,并发量有大幅提高,增加了对Order By、Group By、limit等聚合功能的支持,支持目前主流的大部分数据库。
Mycat支持inner join、leaf/right join、cross join、Full join等方式跨节点join,主要是通过全局表,ER分片,Share Join和catlet(人工智能)四种方式实现。
1、 全局表
一个真实的业务系统中,往往存在大量的类似字典表的表格,它们与业务表之间可能有关系,这种关系,可以理解为“标签”,而不应理解为通常的“主从关系”,这些表基本上很少变动,可以根据主键ID进行缓存,下面这张图说明了一个典型的“标签关系”图:

在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,考虑到字典表具有以下几个特性:
• 变动不频繁
• 数据量总体变化不大
• 数据规模不大,很少有超过数十万条记录。
鉴于此,MyCAT定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
• 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
• 全局表的查询操作,只从一个节点获取
• 全局表可以跟任何一个表进行JOIN操作
将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据JOIN的难题。通过全局表+基于ER关系的分片策略,MyCAT可以满足80%以上的企业应用开发。
全局表配置方式如下(全局表会存储于所以节点):
ER分片
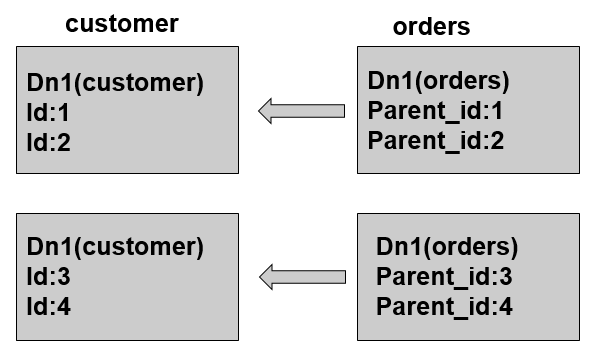
MyCAT借鉴了NewSQL领域的新秀Foundation DB的设计思路,Foundation DB创新性的提出了Table Group的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了JION的效率和性能问题,根据这一思路,提出了基于E-R关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上。customer采用sharding-by-intfile这个分片策略,分片在dn1,dn2上,orders依赖父表进行分片,两个表的关联关系为orders.customer_id=customer.id。于是数据分片和存储的示意图如下:
配置方法如下:
3、 share join
ShareJoin是一个简单的跨分片Join,基于HBT的方式实现。目前支持2个表的join,原理就是解析SQL语句,拆分成单表的SQL语句执行,然后把各个节点的数据汇集。
配置方式如下:
A、A,B的dataNode相同
B、A,B的dataNode不同
4、 Catlet(人工智能)
解决跨分片的SQL JOIN的问题,远比想象的复杂,而且往往无法实现高效的处理,既然如此,就依靠人工的智力,去编程解决业务系统中特定几个必须跨分片的SQL的JOIN逻辑,MyCAT提供特定的API供程序员调用,这就是MyCAT创新性的思路——人工智能。
Mycat里的事务包括以下几种情况:
单SQL不垮分片:事务中的单条SQL在单个节点上执行
单SQL跨分片:事务中的单条SQL在多个节点上执行
事务内多个SQL,在不同的分片上执行
其中,第一种情况,单一SQL仅仅在一个dataNode上执行,此时Mycat事务模式跟标准的数据库事务模式一样,要么提交要么回滚;而对于第二种和第三种的事务,Mycat执行的一种”弱XA事务“模式,此模式的逻辑如下:
首先事务内的SQL在各自的分片上执行并返回状态码,若某个分片上的返回码为ERROR,则Mycat认为事务失败,应用端只能回滚(rollback)事务,Mycat收到回滚指令后,依次回滚事务中涉及到的所有分片;若事务中的所有SQL的执行都返回成功(OK)的返回码,则应用程序提交事务的时候,Mycat会同时向事务中涉及到的节点发送提交事务的指令。例如:
客户端执行如下的指令:
set autocommit=0
update person set name=‘xxxx’ where age >18
commit
如果person表跨分片(dn1,dn2,dn3),则上述SQL将触发如下的执行逻辑
for( dn1,dn2,dn3)
{
set autocommit=0;
update person set name='xxxx' where age >18;
}
if(allOK)
{
for(dn1,dn2,dn3)
{
commit;
}
}
这里称之为弱XA,是因为第二阶段Commit的时候,若某个节点出错了,也无法等节点恢复以后去做Recover操作,重新commit,但考虑到所有的节点都执行成功,Commit指令失败的概率很小,因此这种弱XA事务也已经满足大多数应用的需求,而且性能接近普通事务。
在实现分库分表的情况下,数据库自增主键已无法保证自增主键的全局唯一。为保证数据一致性,这个问题是必须解决的,MyCat 提供了全局sequence,并且提供了包含本地配置和数据库配置等多种实现方式。
本地配置方式MyCAT将sequence配置到文件中,当使用到sequence中的配置后,MyCAT会更下classpath中的equence_conf.properties文件中sequence当前的值。配置方式如下:
--在sequence_conf.properties文件中做如下配置:
GLOBAL_SEQ.HISIDS=
GLOBAL_SEQ.MINID=1001
GLOBAL_SEQ.MAXID=1000000000
GLOBAL_SEQ.CURID=1000
同时还需要将server.xml中的sequnceHandlerType设置为0.
本地配置的特点是本地加载,读取速度较快,但是当MyCAT重新发布后,配置文件中的sequence会恢复到初始值。
数据库方式在数据库中建立一张表,存放sequence名称,sequence当前值(current_value),步长(increment)等信息。配置方式如下:
首先需要将server.xml中的sequnceHandlerType设置为1,然后在数据库中创建下列对象:
1、创建MYCAT_SEQUENCE表
CREATE TABLE MYCAT_SEQUENCE (name VARCHAR(50) NOT NULL,current_value INT NOT NULL,increment INT NOT
NULL DEFAULT 100, PRIMARY KEY(name)) ENGINE=InnoDB;
插入一条seqence
INSERT INTO MYCAT_SEQUENCE(name,current_value,increment) VALUES (‘GLOBAL’, 99999, 10);
2、创建3个fuction,分别用来设置sequence、获取当前sequence、获取下一个sequence。
DROP FUNCTION IF EXISTS mycat_seq_setval;
DELIMITER
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),value INTEGER) RETURNS varchar(64) CHARSET utf-8
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = value
WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END
DELIMITER;
DROP FUNCTION IF EXISTS mycat_seq_currval;
DELIMITER
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS varchar(64) CHARSET utf-8
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval=“-999999999,null”;
SELECT concat(CAST(current_value AS CHAR),“,”,CAST(increment AS CHAR)) INTO retval FROM MYCAT_SEQUEN CE
WHERE name = seq_name;
RETURN retval;
END
DELIMITER;
DROP FUNCTION IF EXISTS mycat_seq_nextval;
DELIMITER
CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS varchar(64) CHARSET utf-8
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END
DELIMITER;
3、在sequence_db_conf.properties中指定sequence相关配置在哪个节点上。
1. 达到一定数量级才拆分(800万);
2. 不到800万但跟大表(超800万的表)有关联查询的表也要拆分,在此称为大表关联表;
3.大表关联表如何拆:小于100万的使用全局表;大于100万小于800万跟大表使用同样的拆分策略;无法跟大表使用相同规则的,可以考虑从java代码上分步骤查询,不用关联查询,或者破例使用全局表;
4.破例的全局表:如item_sku表250万,跟大表关联了,又无法跟大表使用相同拆分策略,也做成了全局表。破例的全局表必须满足的条件:没有太激烈的并发update,如多线程同时update同一条id=1的记录。虽有多线程update,但不是操作同一行记录的不在此列。多线程update全局表的同一行记录会死锁。批量insert没问题;
5.拆分字段是不可修改的;
6.拆分字段只能是一个字段,如果想按照两个字段拆分,必须新建一个冗余字段,冗余字段的值使用两个字段的值拼接而成(如大区+年月拼成zone_yyyymm字段);
7. 拆分算法的选择和合理性评判:按照选定的算法拆分后每个库中单表不得超过800万;
8. 能不拆的就尽量不拆。如果某个表不跟其他表关联查询,数据量又少,直接不拆分,使用单库即可。
上一篇:浅析虚拟化环境网卡绑定模式
下一篇:应用的自动化测试与应用性能分析

新炬网络公众号